Your First Chat
Starting Your First Conversation with Llama 3.2
Now that Ollama is installed, let’s download a model and start chatting!
Step 1: Download Llama 3.2
Llama 3.2 is our primary model for this workshop. It’s efficient, capable, and runs well on consumer hardware.
Using the Ollama GUI
-
Open the Ollama application
-
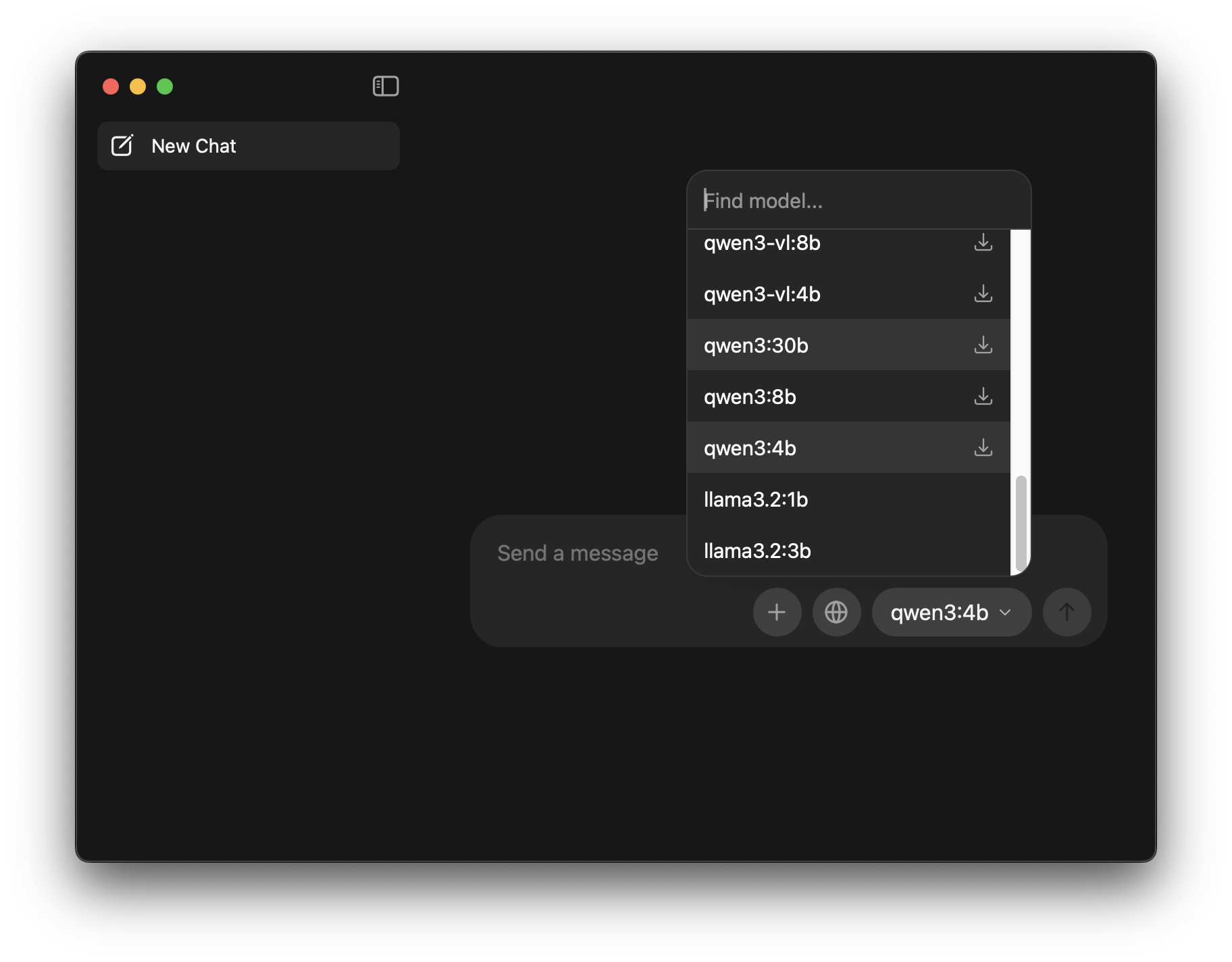
Click the Model Selector dropdown at the bottom of the window
You’ll see the current model name (or “Find model…”) in a dropdown button.
-
Search for “llama3.2” in the “Find model…” search box
Type “llama3.2” in the search field that appears
-
Select and download “llama3.2:3b”
You’ll see options like:
llama3.2:1b(smaller, faster)llama3.2:3b(recommended for workshop)
Click the download icon (↓) next to
llama3.2:3bto download it. -
Wait for download to complete
Download size: ~2 GB for the 3B version Time: 5-15 minutes depending on your internet speed
The download icon will change to indicate when the model is ready.
Using the Command Line
Open your terminal (macOS/Linux) or Command Prompt (Windows) and run:
ollama pull llama3.2You’ll see output like:
pulling manifest
pulling 8eeb52dfb3bb... 100% ▕████████████████▏ 2.0 GB
pulling 73b313b5552d... 100% ▕████████████████▏ 120 B
pulling 0ba8f0e314b4... 100% ▕████████████████▏ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
successAlternative: Download the 1B version (if you have limited RAM):
ollama pull llama3.2:1bStep 2: Verify the Model Downloaded
Let’s confirm the model is ready to use.
GUI Method
-
Click the model selector dropdown at the bottom of the window
-
Verify llama3.2 appears in the list
After download completes,
llama3.2:3b(orllama3.2:1b) should appear in the model list without a download icon next to it
CLI Method
ollama listExpected output:
NAME ID SIZE MODIFIED
llama3.2:latest 8eeb52dfb3bb 2.0 GB 2 minutes agoStep 3: Your First Conversation
Now for the exciting part - talking to your local LLM!
Using the Ollama GUI
-
Select llama3.2:3b from the model dropdown at the bottom of the window
Click the dropdown button and choose
llama3.2:3bfrom the list -
Type a message in the “Send a message” input box
Try this simple prompt:
Hello! Please introduce yourself and tell me what you can help with. -
Press Enter or click the Send button (↑)
-
Watch the response generate
You’ll see the model’s response appear in the chat area in real-time (streaming)
Expected Response (may vary):
Hello! I'm Llama, a large language model trained by Meta AI. I'm here to
assist you with a wide variety of tasks, including:
- Answering questions on various topics
- Generating text and creative content
- Helping with writing, editing, and proofreading
- Providing information and explanations
- Assisting with problem-solving and brainstorming
- And much more!
I'm running locally on your machine, which means your conversations stay
private and don't require an internet connection. How can I help you today?Using the CLI
Start an interactive chat session:
ollama run llama3.2You’ll see a prompt:
>>>Type your message and press Enter:
>>> Hello! Please introduce yourself and tell me what you can help with.The model will respond directly in the terminal.
CLI Commands:
- Type your messages and press Enter
- Use
/byeto exit - Use
Ctrl+Dto exit - Scroll up to see conversation history
Step 4: Experiment with Basic Prompts
Try these prompts to get familiar with your local LLM:
Factual Question
What are the three laws of thermodynamics?Creative Task
Write a haiku about local AI running on personal computers.Coding Help
Write a Python function to check if a number is prime.Explanation
Explain machine learning to a 10-year-old.Translation
Translate "Hello, how are you?" to Spanish, French, and German.Step 5: Understanding the Interface
The Ollama GUI provides a clean, simple interface:
Main Interface Elements
- New Chat button (top left): Start a fresh conversation
- Model selector (bottom): Choose which model to use
- Send button (↑): Submit your message
- Attachment button (+): Add files to your conversation (if supported)
- Globe icon: Language or network settings
Step 6: Upload Files (Optional - If Supported)
If your Ollama GUI version supports file uploads:
-
Drag and drop a text file into the chat window
-
Ask questions about the file:
Summarize this document in 3 bullet points.What are the main themes in this text?
Understanding What Just Happened
Congratulations! You just:
✓ Downloaded a 3-billion-parameter language model to your computer ✓ Ran it entirely locally (no cloud services) ✓ Had conversations that stayed completely private ✓ Experimented with different types of prompts
Key Points:
- Everything is Local: The model runs on your CPU/GPU, using your RAM
- Privacy: No data leaves your computer
- Offline Capable: Works without internet (after model download)
- Free: No per-use costs or subscriptions
- Customizable: You control all settings and behavior
Common Questions
Q: How fast should responses be?
A: It varies by hardware:
- Fast (< 1 second per word): Modern Apple Silicon, high-end GPUs
- Medium (1-3 seconds per word): Recent CPUs with 16+ GB RAM
- Slower (3-5 seconds per word): Older hardware, minimum specs
Speed is acceptable as long as responses are coherent and useful.
Q: Can I run multiple models?
A: Yes! Download more models with ollama pull [model-name]. Switch between them in the GUI dropdown or CLI.
Q: How much memory does it use?
A: Llama 3.2:
1bmodel: ~1.5 GB RAM3bmodel (default): ~2.5 GB RAM- Plus overhead: ~1-2 GB
On an 8 GB system, the 3B model should run comfortably.
Next Steps
Now that you can chat with your local LLM, let’s learn how to get better results through effective prompting:
Troubleshooting
If you encountered any issues: